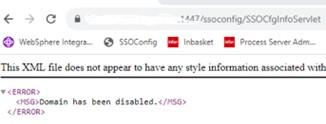
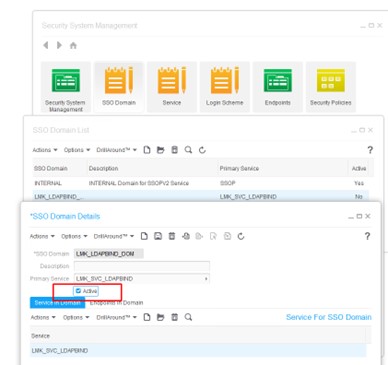
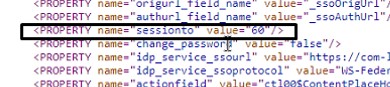
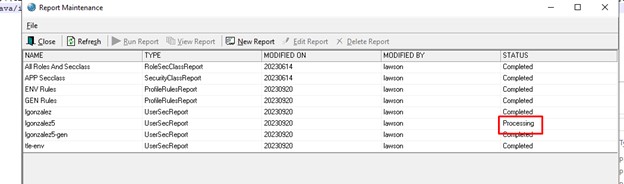
In recent years, it’s no doubt that some technologies are becoming more prevalent than others. What’s more is when these technologies work together. Peter Pluim, President of SAP’s Enterprise Cloud Services & SAP Sovereign Cloud Services, believes from past trends and the forward outlook this year, that this is the year of Cloud ERP (enterprise resource planning), powered by Business AI (artificial intelligence). Pluim shares an article on Forbes stating that these two technologies, along with sustainability, will reshape the current business landscape. “Looking ahead to 2024, the strategic adoption of advanced Business AI-powered analytics within Cloud ERP will be crucial for proactive planning and informed decision-making, as well as driving improved efficiency,” he says. Below are the many ways these technologies will empower the digital landscape this year:
Cloud Computing Continues to Expand. “The need for innovative business models and revenue streams, coupled with the ability to pivot swiftly according to business needs, has intensified. Cloud ERP emerges as the fastest route to a complete digital transformation and the cultivation of advanced business capabilities, touching every facet of a company.”
AI-Powered ERP and Automation. “2024 promises to be the year of Business AI-infused Cloud ERP. Scott Russell, member of the Executive Board of SAP writes that with AI, we can now imagine real-time inventory optimized by predictions, automated purchases triggered by demand forecasts, and self-healing systems that fix bottlenecks before they become problems.”
More Powerful ERP Analytics. “ERP analytics are no longer just about looking at the past; they’re also about understanding the present and shaping the future. As ERP analytics continues to evolve, its role in shaping a responsible and resilient future for businesses will only grow.”
ERP Drives More Sustainable Operations. “The integration of Cloud ERPs with generative AI is fast-tracking sustainability goals by providing a practical “Green Ledger” for tracking emissions, optimizing the supply chain, and ensuring regulatory compliance for a more environmentally conscious future.”
Sovereign Cloud Market on the Ascent. “Deloitte predicts the global sovereign cloud market will hit $41 billion in 2024, a 16% jump from 2023, driven by government cloud initiatives offering compliance-first solutions. It’s a compelling blend that ensures more secure, localized data management, while preserving the flexibility and scalability that customers value in today’s dynamic business environment.