Are you getting this error when updating a user’s record in ISS stating
loadResource(): returned identity [User:] already exists?
If so, then this error is due to missing extended attributes in LDAP. The extended attributes are what allow ISS to know that the user exists in LMK and are created when a user is added via ISS or the user is included in a sync.
Simply run a full sync via the ISS webpage to create the extended attributes
To prevent this issue going forward you should add a list-based sync to the user add process. This should resolve the error completely.
Tech expert Brian Sommer shares an article on Diginomica highlighting Infor’s product update presentation earlier this March. The almost 2-day event at their New York HQ covered many innovations that the enterprise resource planning (ERP) vendor has been working on in recent years. Sommer provides key takeaways below:
Infor will be releasing a flurry of product announcements starting next month and continuing into the Fall.
Infor’s vertical/micro-vertical focus has been a key activity within the firm’s development and implementation teams. It is also a key competitive differentiator for Infor.
Industry functionality is one of Infor’s tools to make their solutions highly tailorable to current and prospective customers. That vertical functionality is being paired with other technology stack tools that include process mapping, no/low-code workflow automation, best practice and process workflow templates and more.
Advanced technologies (notably Business Intelligence, Process Intelligence and Artificial Intelligence) are part of all Infor vertical solutions.
Infor no longer resembles a firm comprised of numerous acquired software firms. We went almost two days without hearing names like: Lawson, Baan, SSA, Walker, etc. The focus is on verticals now – not acquired technologies.
Infor’s private ownership, by Koch Industries, will likely drive different investment decisions that other software vendors face from private equity and venture capital owners/investors. Specifically, readers should expect Infor to reinvest earnings and focus on long-term growth items.
https://www.nogalis.com/wp-content/uploads/2013/04/Infor__Logo.jpg566565Angeli Mentahttps://www.nogalis.com/wp-content/uploads/2013/04/logo-with-slogan-good.pngAngeli Menta2024-04-08 15:27:102024-04-08 17:43:11Infor’s product update – what buyers can expect to encounter
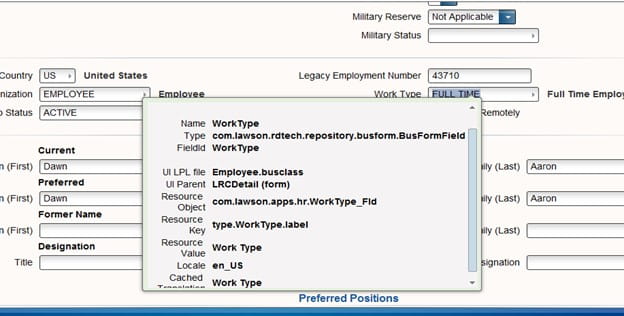
Go to the field and do a Ctrl + shift and left click on your mouse, this will give you the Business class that you will need to have and the name of the field. In this example we will be looking at the Employee business and the field Work Type
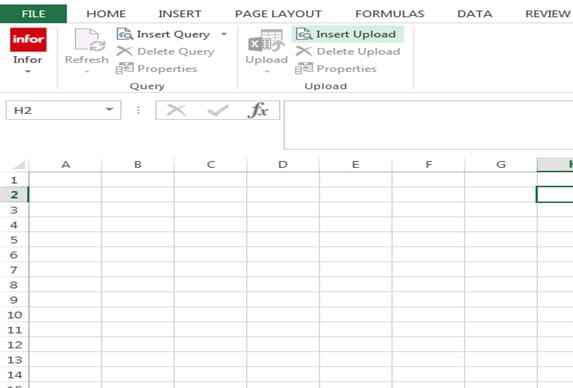
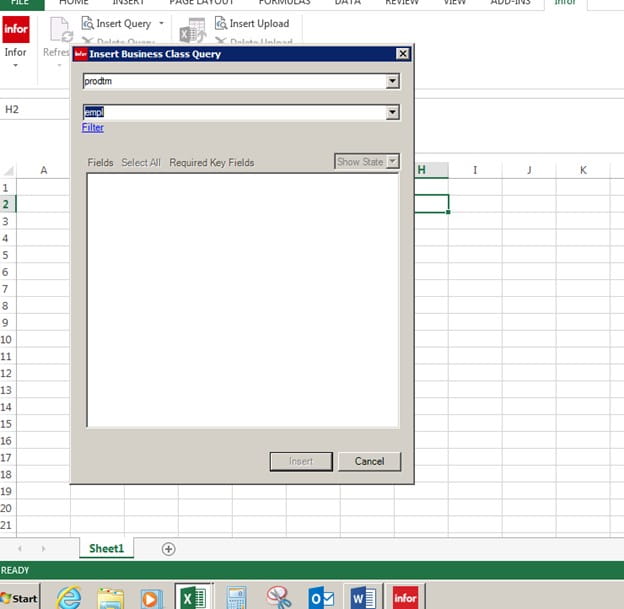
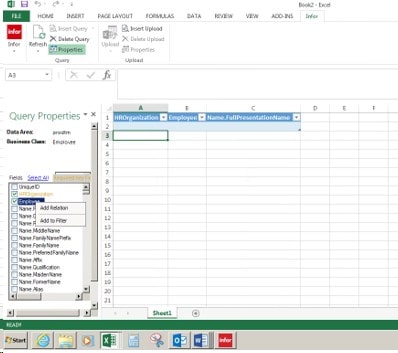
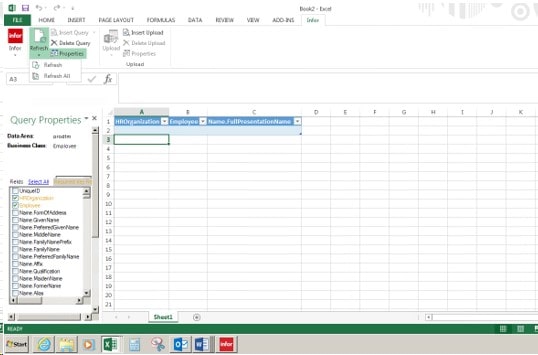
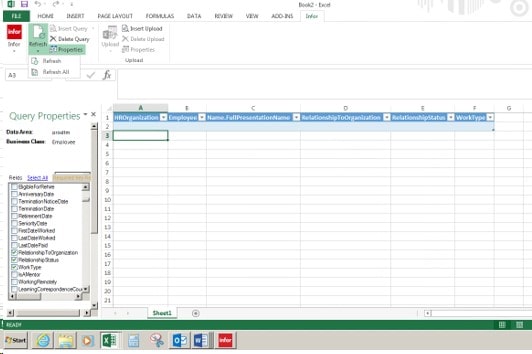
Let’s open up Excel and go to the Infor tab, and we will be doing a query. Go to the Insert Query and click on the drop down arrow
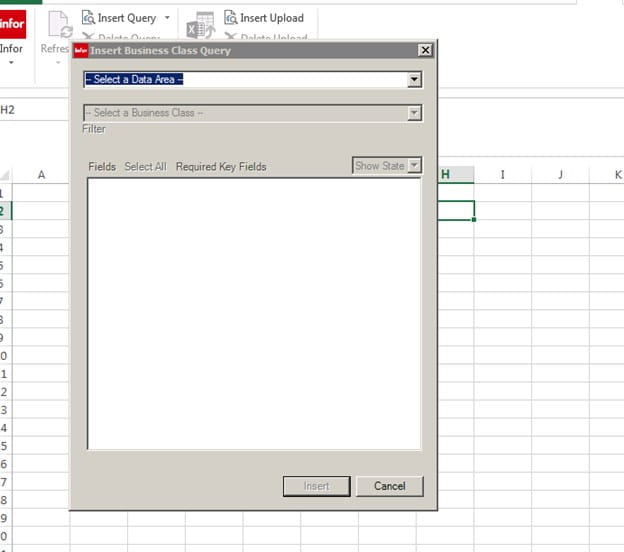
This box will appear, do a drop down and pick the environment name for your Data Area
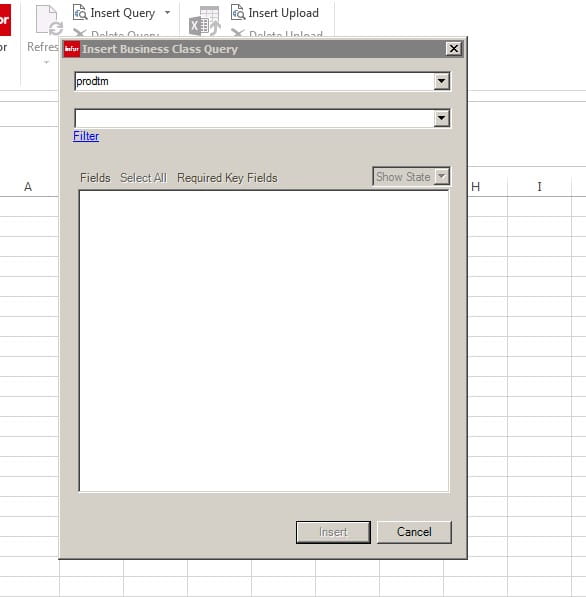
In the second box, we will be typing in the business class, in this example it will be Employee
As you are typing in the second box the business class will appear
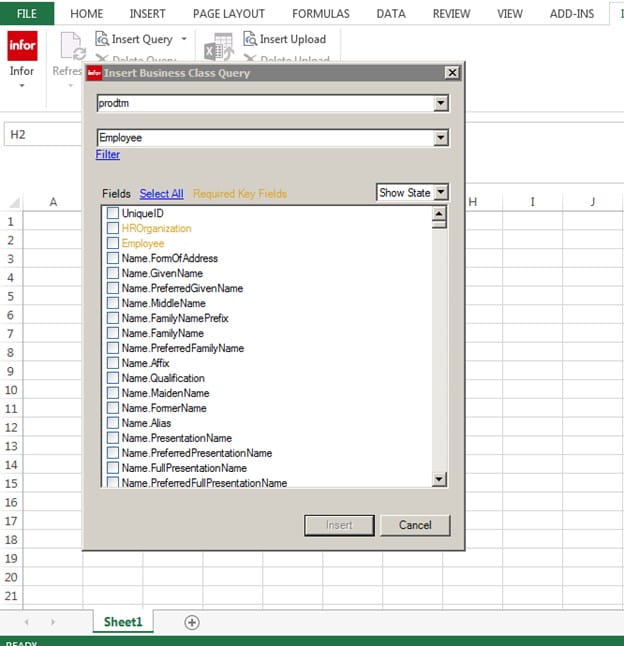
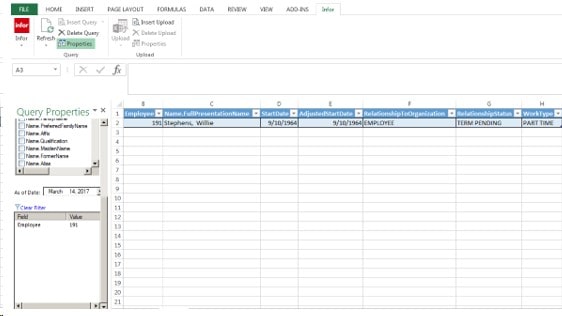
Now you see all the field that you can pick from under Employee Business Class. The ones that are Orange are required fields and need to be in your Query. The Employee is the Employee ID number
We will be using for this example the following fields,
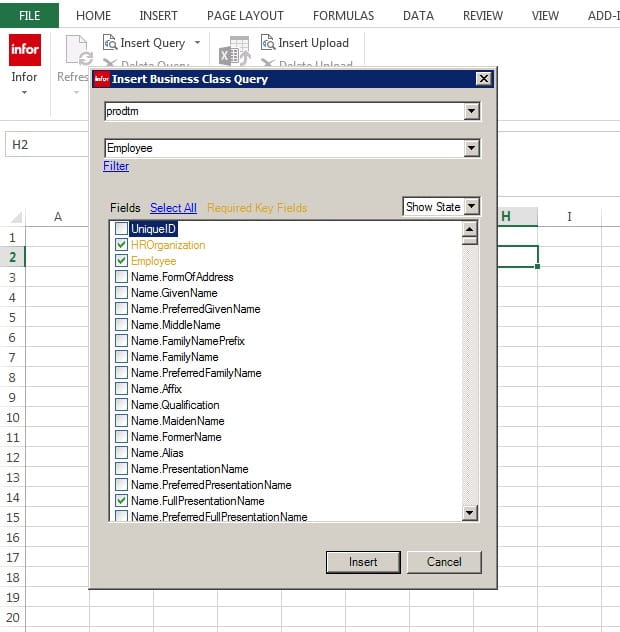
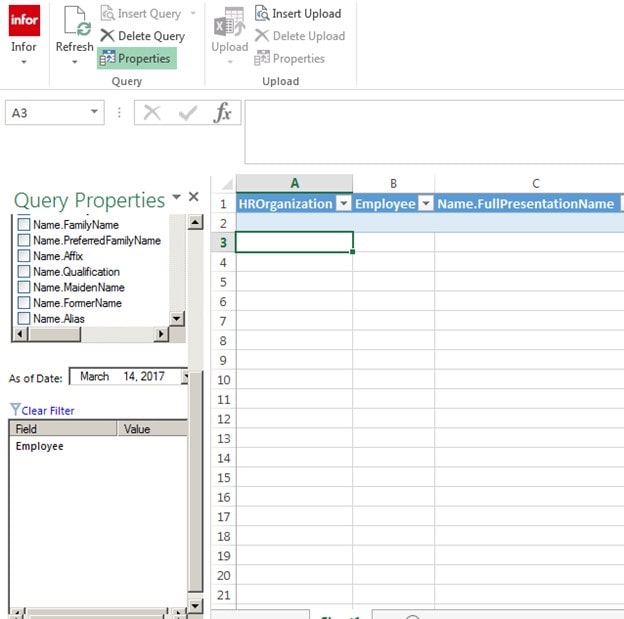
HROrganization
Employee
Name.FullPresentationName
Scroll down and pick
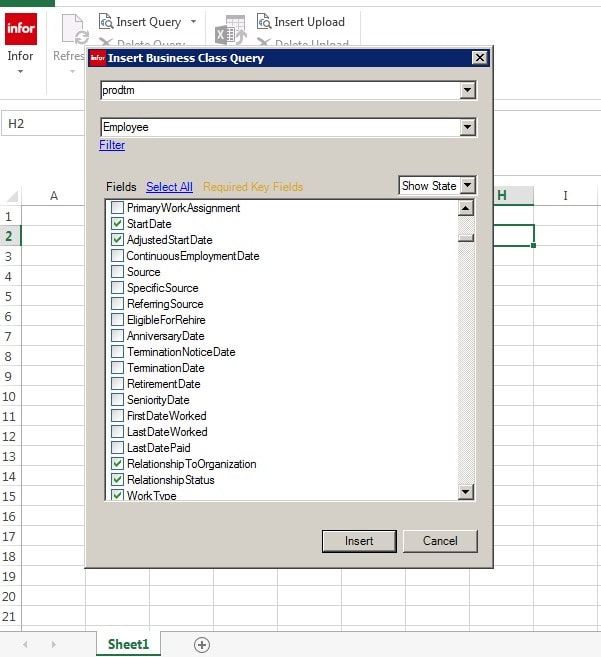
StartDate
Adjusted Start Date
Relationship to Org
Relationship Status and click on Insert
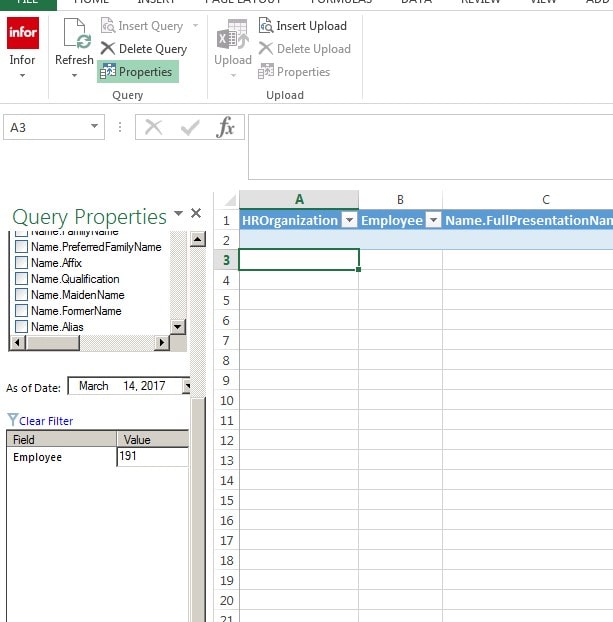
Go to the Employee and rich click on your mouse, pick Add to Filter
Go to the bottom of the Insert, and you will see Employee. Next to Employee, under Value enter your Employee ID number.
Like Below
Now click off that field
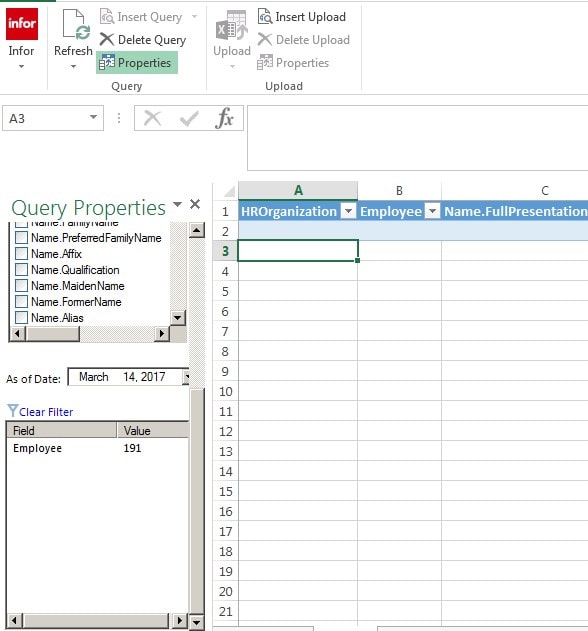
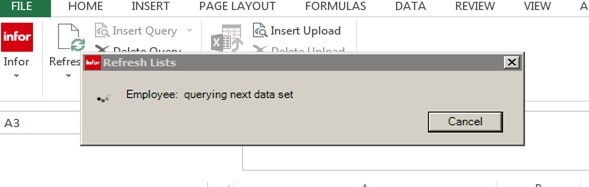
Go to Refresh at the top of the page by the Infor sign and do a drop down
We will be clicking on Refresh
This box will appear
Your Information will appear,
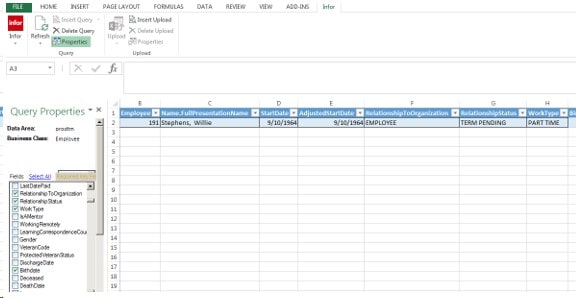
Now let add Work Type to our report, Find the Field Work Type and check the box,
Click on Refresh again and the Work Type Information will be part of your Report
https://www.nogalis.com/wp-content/uploads/2024/03/How-to-do-a-Spreadsheet-Designer.jpg470470Angeli Mentahttps://www.nogalis.com/wp-content/uploads/2013/04/logo-with-slogan-good.pngAngeli Menta2024-04-05 08:04:342024-03-29 16:20:23How to Do a Spreadsheet Designer
At the heart of a business’s operations is usually an enterprise resource planning (ERP) system running all your processes. So how do you decide on the best one for your business. More importantly, how can you properly implement it with no hitch and run it with optimal performance? Forbes Council Member Madhavi Godbole, a seasoned expert in the field of ERP and the senior vice president at Apolisrises Inc., shares an article with her personal insights and lessons learned in implementing a successful ERP.
Lesson 1: Strategic Alignment And Clear Objectives. “One of the pivotal lessons I have learned pertains to the critical importance of strategic alignment and establishing clear objectives before embarking on any major technological initiative, particularly ERP implementation. It is imperative to align technology initiatives with overarching business goals and ensure every stakeholder comprehends the purpose and expected outcomes. By fostering a shared vision and understanding across the organization, leaders can mitigate resistance, streamline decision-making and cultivate a culture of collaboration conducive to successful ERP implementation.”
Lesson 2: Robust Change Management And Stakeholder Engagement. “Another indispensable lesson revolves around the necessity of robust change management and proactive stakeholder engagement throughout the ERP implementation process. Effective change management entails more than just technical proficiency; it necessitates empathetic leadership, open communication, and a keen awareness of organizational dynamics. Engaging stakeholders early and involving them in the decision-making process fosters a sense of ownership and buy-in, mitigating resistance and maximizing the likelihood of successful adoption. Additionally, fostering a culture of continuous learning and adaptation empowers teams to navigate challenges and capitalize on opportunities.”
Lesson 3: Iterative Approach And Continuous Improvement. “Lastly, my journey has underscored the value of adopting an iterative approach to ERP implementation and embracing a culture of continuous improvement. In today’s rapidly evolving business landscape, agility and adaptability are paramount. Rather than striving for perfection from the outset, organizations should prioritize incremental progress, leveraging feedback loops and agile methodologies to iteratively refine processes and enhance system capabilities. By embracing a mindset of continuous improvement, tech leaders can foster innovation and optimize performance. Looking back on my personal journey, during a large global ERP implementation, the significance of strategic alignment became unmistakably evident. In this implementation, the finance team emphasized strict budgetary controls and prioritized cost reduction measures, while the procurement team focused on optimizing supplier relationships and ensuring timely delivery of goods and services—with both departments advocating for divergent strategies. We had to champion an open dialogue and align our efforts with broader organizational goals in order to see the right way forward for the organization and merge the two departments’ goals.”
Technology is ever-growing and will not slow down with new innovative methods any time soon. With new technologies or stronger technologies surfacing regularly, this becomes a concern for protecting your data from breaches in every new way possible. EY’s Emerging Tech at Work 2023 survey reveals that 89% of employees believe adopting emerging tech benefits their company. Still, cybersecurity risk can be a barrier to adoption. In the same survey, approximately 73% of employees are concerned about the cybersecurity risks associated with generative AI, and 78% worry about quantum computing. Additionally, only one in five executives see their organizations’ cybersecurity measures as effective for today and the future. Forbes Council Member, Steve Gickling and CTO of Calendar – a place for unified calendars and all your scheduling needs – shares an article depicting 4 effective ways you can defend your business from data breaches.
Start with clear-cut training. “Combining upskilling and streamlined practices is often a solid approach to addressing the human element. If employees aren’t safeguarding their passwords, there’s probably a best practice they don’t fully understand. Teaching them how to recognize phishing attempts and social engineering tactics is a start, but it’s even better to educate them on why automated password management solutions simplify the use of internal technology and protect the organization.”
Shield the cloud. “Organizations rely on cloud service providers for security, but that doesn’t mean those providers are necessarily protecting their clients’ data adequately. Anything from incorrect configurations to insufficient security permissions can leave a company vulnerable to cybercriminals seeking an opportunity. Auditing cloud providers and solutions can sort out who’s responsible for what. Find out what vulnerabilities providers see in their solutions and follow their recommendations on how to close the loopholes. Tech leaders can also consider implementing cloud monitoring and security software, which looks for potential issues. These vulnerabilities might be unauthorized users, a lack of data encryption and/or weak access controls. Monitoring software could also reveal whether data storage isn’t private, increasing its exposure to malicious actors.”
Monitor for data leaks. “What if your employees are using the same passwords for both their personal and professional accounts? The leaked information could be from a vendor’s software platform. Cybercriminals are known to try exposed, easy-to-guess and common passwords. They may look at online org charts, hoping to find a match between a leaked personal password and an employee’s account. When implementing a data leak detection solution, workplaces need to find tools that will help them accomplish the best practices for their chosen software. To maximize the software they’ve established, a few key steps are to regularly train employees on using the most current version, constantly monitoring any potential risks and always maintaining secure processes to access the data.”
Minimize data retention. “Storing data on your network comes with inherent risks, including the chance it will fall into unwanted hands. By only keeping what’s necessary, you can reduce the probability that sensitive data will become exposed. Enacting data retention procedures should thus be part of your organization’s critical cybersecurity plan. Another aspect to minimize is the locations where information is housed. Streamlining the amount of places the company stores data can reduce vulnerabilities. The fewer places sensitive information is, the less potential there is for exposure. As you condense data storage locations, however, be sure to keep close tabs on what data is being stored and where.”
https://www.nogalis.com/wp-content/uploads/2024/04/data-cyber-security.jpg398600Angeli Mentahttps://www.nogalis.com/wp-content/uploads/2013/04/logo-with-slogan-good.pngAngeli Menta2024-04-03 11:04:322024-04-02 18:04:094 Effective Ways To Defend Your Business From Data Breaches
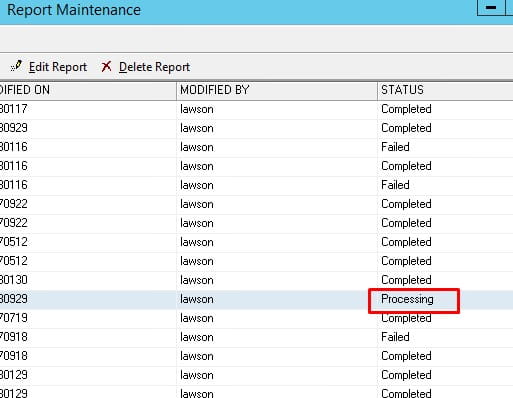
After implementing this change, you will need to perform the following restarts:
Stop your WebSphere application server or cluster for this environment.
Stop the Lawson environment using the stoplaw command.
Start the Lawson Environment using the startlaw command.
Start the WebSphere application server or cluster for this environment.
Execute the report again to verify that it completes successfully.
https://www.nogalis.com/wp-content/uploads/2024/03/Lawson-Security-Administrator-LSA-Reporting-is-stuck-in-processing-status.jpg470470Angeli Mentahttps://www.nogalis.com/wp-content/uploads/2013/04/logo-with-slogan-good.pngAngeli Menta2024-04-02 08:18:022024-03-29 16:19:49Lawson Security Administrator (LSA) Reporting is stuck in “processing” status
When it comes to backing up your organization’s valuable data, many folks are either stuck in old less secure ways or are simply not backing them up correctly – or at all. The point of backing up data is to have it be restored in a company’s system if they lose it somehow either due to cybersecurity attacks, a natural disaster, or data center and system failures. Eric Herzog, Forbes Council Member and Chief Marketing Officer at Infinidat, shares an article explaining from an IT perspective how organizations should go about securing their backed up data. He states, “From an IT perspective, backup targets have usually been measured on how fast they are, their ability to reduce the amount of data backed up and how economical they are for storage. However, ransomware and malware attacks have recently been focusing on backup infrastructure, as well as data on primary storage… Cybercriminals have learned that, to be effective, they need to not only attack data on primary storage but also disrupt backup storage.” Attacking backup storage allows cybercriminals to make a company even more vulnerable when attacking their main servers as well. This would be difficult to nearly impossible for a company to recover from a cyberattack to your backup data. With these new, more sophisticated approaches to attacking backup storage, cybercriminals are slowly “poisoning” the copies of data. With this known tactic, IT leaders and Security divisions at companies are focusing on added cybersecurity to their backup data as well. “In light of this new threat scenario that virtually all enterprises now face, the backup storage needs to take on additional responsibilities, such as expediting near-instantaneous cyber recovery or hosting recoveries with a dual role,” says Herzog. “This is noteworthy because, even if backup storage fights off a ransomware or malware attack, the cyberattack may have already reached production data on IT systems and primary storage. Enterprises need a higher level of cyber resilience to ensure that they are equipped to handle ransomware, malware and other cyberattacks.” According to Herzog, cyber secure backup storage needs to incorporate the following capabilities: immutability of data, high availability, data encryption, multifactor authentication, automation or a certain level of artificial intelligence, and cyber storage guaranteed service level agreements (SLAs). He concludes that it is best to look for cyber secure backup storage that utilizes the same underlying operating system that facilitates speedy backups. This varies based on your specific enterprise’s requirements and you may need a software-defined system that maximizes available storage capacity and offers data deduplication, such as a purpose-built backup appliance. But for those enterprises that have a higher priority on the backup target hosting application and data recovery, Herzog notes that choosing a primary storage platform that is repositioned as a backup target is the more appropriate choice.
https://www.nogalis.com/wp-content/uploads/2020/03/warehouse-management-storage-logistics.jpg399600Angeli Mentahttps://www.nogalis.com/wp-content/uploads/2013/04/logo-with-slogan-good.pngAngeli Menta2024-04-01 14:07:352024-04-01 18:19:29What IT Leaders Need To Know About Cyber Secure Backup
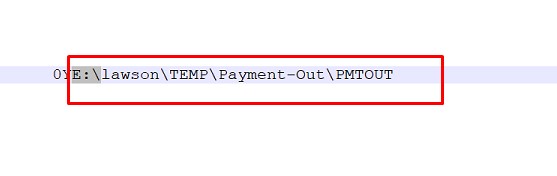
Once you dump this job, edit it in notepad or notepad++ and locate the incorrect path, example below:
Update this path ONLY to what you need it to be and use jobload to reload it:
jobload -c -o Job YourPR160JOBNAME.txt
Then recover the job and it should put the file in the correct path.
https://www.nogalis.com/wp-content/uploads/2024/03/PR160-In-Recovery-but-cant-delete-and-need-to-update-the-file-path-parameter.jpg470470Angeli Mentahttps://www.nogalis.com/wp-content/uploads/2013/04/logo-with-slogan-good.pngAngeli Menta2024-03-29 08:01:112024-03-28 15:03:30PR160 In Recovery but can’t delete and need to update the file path parameter
Artificial Intelligence (AI) is already providing value to businesses in ways that may not be obvious. Walter Sun, Global head of artificial intelligence at SAP, shares a great read on ERP Today about how much value AI is providing for your business. One example he shares is German retailer Lidl saw significant improvements like 15% better inventory management and 20% decrease in waste by bringing in historical business data, consumer sentiment, financial information and weather forecasts to better predict demand in their stores. SAP has also launched an AI tool called Joule which can answer complex business questions by analyzing company data. A user could ask how to improve store performance and Joule would generate an answer combining relevant information from different sources. While AI capabilities like generating art or text seem impressive, the real value lies in using data to enhance decision making and boost business performance. As supply chain management, manufacturing and customer experience all benefit from AI, it will allow any employee to access trusted insights without needing analytical expertise. The future potential for AI adoption across industries is huge. If implemented responsibly, Sun explains, AI could transform industries in coming years by enabling more accurate short-term forecasting, proactive disruption mitigation, optimized manufacturing while reducing inventory costs, and truly personalized customer experiences. Emerging regulations will provide guidance to build trust as AI gradually integrates into workplaces. Developers also need to center people, focus on customers’ critical processes, leverage real business data and take ethics seriously.
https://www.nogalis.com/wp-content/uploads/2018/11/ai-artificial-intelligence-hr.jpg420650Angeli Mentahttps://www.nogalis.com/wp-content/uploads/2013/04/logo-with-slogan-good.pngAngeli Menta2024-03-28 16:39:402024-03-29 17:00:12Making the Most of Business AI
Infor Nexus VP of product marketing and strategy Heidi Benko this month became the recipient of 2024 Pros to Know Award by Supply & Demand Chain Executive. This award recognizes outstanding executives whose accomplishments offer a roadmap for other leaders looking to leverage supply chain for competitive advantage. Marina Mayer, editor-in-chief of Food Logistics and Supply & Demand Chain Executive, comments, “Many of today’s supply chain pros are more than just leaders within their space; they’re innovators, decision makers, pioneers of change and growth. They’ve spent the last year (and more) creating safer, more efficient supply chains. New this year, we broke the award down into four distinct categories: Top Warehousing Stars; Top Procurement Stars; Rising Stars; and Lifetime Achievement. These winners continue to go above and beyond to overcome challenges, advance supply chain management and make the impossible, possible.” Per the news release, Benko has been an integral part of the Infor Nexus team to champion sustainability and social responsibility top priorities across the supply chain. She works closely with customers, prospects, industry leaders and analysts to drive greater awareness of how the unique, single-instance global supply chain platform can help companies run more efficient, profitable and sustainable supply chains.
https://www.nogalis.com/wp-content/uploads/2013/04/Infor__Logo.jpg566565Angeli Mentahttps://www.nogalis.com/wp-content/uploads/2013/04/logo-with-slogan-good.pngAngeli Menta2024-03-27 11:19:102024-03-28 17:22:44Supply & Demand Chain Executive Names Heidi Benko as Recipient of 2024 Pros to Know Award