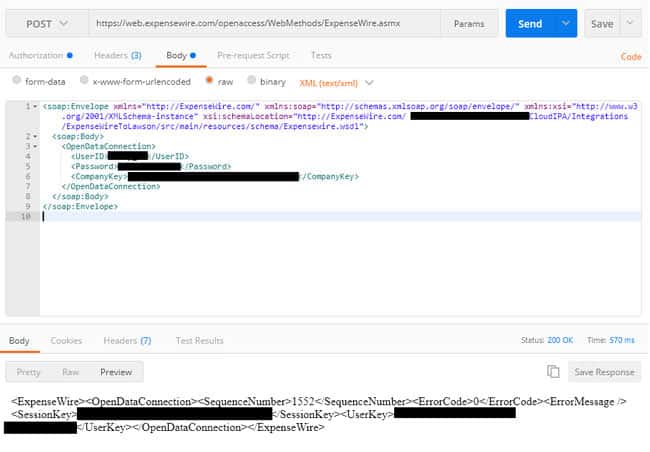
Enterprise Resource Planning (ERP) systems can bring immeasurable benefits to any company. It is the backbone of any organization, playing a crucial role in keeping all operations running smoothly. Though, like any part of a business, it is susceptible to complications, leading to costly mistakes and lasting damages. Unfortunately, no company is immune to the devastating impacts of an ERP failure. In 2000, Nike lost $100 million in sales due to a failed supply chain project. Right before Halloween in 1999, Hershey’s was unable to distribute $100 million worth of chocolate because the company’s ERP implementation failed. In 2004, A buggy ERP implementation prevented nearly 27,000 University of Massachusetts students to register for classes or collect financial aid checks.
The good news is that ERP failured can be avoided. Below are lessons learned from ERP failures of the past to ensure future implementations run better.
- Expect Extended Timelines and Plan Accordingly
- Set Realistic Budget Expectations
- Be Patient and Prepared to Problem Solve
- Know What You Really Need
While most businesses make setup for ERP systems a breeze, it can be easy to get overwhelmed by the challenges thereafter. ERP systems, even the best of the best, come with their fair share of complexities. Keeping in mind the lessons learned from past failures, your next ERP implementation can drive efficiency and security in your business and improve operations management.
For Full Article, Click Here