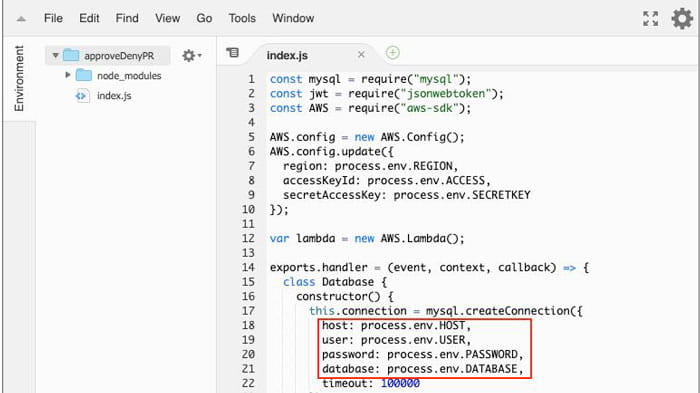
The automobile has gone a long way in design, speed, efficiency and most importantly technology. Today, vehicles are smarter and safer than ever and there’s no denying the cars of the future will become smarter, safer and more advanced. An article from The Burn-In shares a few advances in car technology that have made driving a bit safer and easier for our commute.
- Blind-Spot Detection – No matter how much design and input is put into a car, there will always be some blind spots for the driver. Blind-spot detection is a great addition for a driver to have another set of “eyes” when having to deal with fast lanes, incliment weather and merging into traffic.
- Rearview Camera – Rearview cameras help drivers be a bit more careful when backing out or into a space. It’s almost standard in new cars these days and the added safety of the rearview camera will detect if anything is in your way so you can safely wait to back out.
- Fatigue Detection – Whether it’s a road trip or being stuck in traffic after a long day at work, fatigue detection is a great addition to cars as it dings and asks or reminds you to take a break if you need one. Fatigue detection is done by a combination of things – drive time, speed change, lane swerving, etc.
- Forward Collision Warning – Per the article, “Whether a vehicle suddenly slammed on the brakes ahead of you or you simply got distracted, forward collision warning is a must-have safety feature for all drivers. Forward collision warning, or automatic emergency braking, uses radar to detect hazards ahead, such as cars and pedestrians, to determine whether your speed and distance can result in a crash.”
- Facial Recognition Software – Iphones aren’t the only devices that are taking advantage of facial recognition software. Cars are adding this personal feature as well. Per the article, “Facial recognition software in vehicles works by scanning your face to determine if you’re looking down, using a phone, or getting distracted. If the software notices any dangerous or alarming behaviors, it will issue warnings. While this software is still in its beginning phases, you can expect it to be common in most cars a few years from now.”
The automobile has come a long way and many players are challenging the competition by being one step ahead with technology. Pretty soon we might actually have those self-driving cars.