If you want to use one System Command Node to run more than one command, simply concatenate the commands with “&&”. The output of the System Command Node will be the combined results of all the commands. For example:
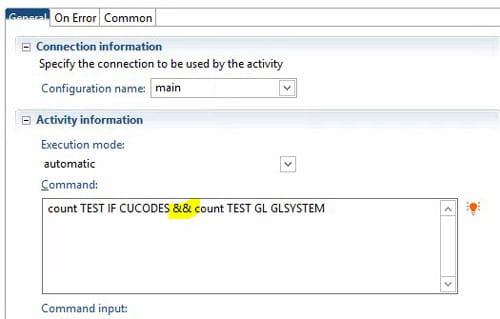
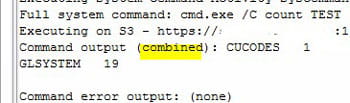
If you want to use one System Command Node to run more than one command, simply concatenate the commands with “&&”. The output of the System Command Node will be the combined results of all the commands. For example:

Microsoft is hardening their security with LDAP channeling and LDAP signing in an update coming soon. Any applications that rely on LDAP connections to Active Directory Domain Services (AD DS) or Active Directory Lightweight Directory Services (AD LDS) need to be converted to LDAPS. LDAPS is a secure connection protocol used between applications like Lawson and the Network Directory or Domain Controller. Below are the potential impacted Lawson applications mentioned by Infor in a recent KB Article.
Impacted Lawson applications:
Infor has recommended that on-premise clients configure the impacted applications and have provided KB Articles on how to perform these tasks.
Some important things to note:

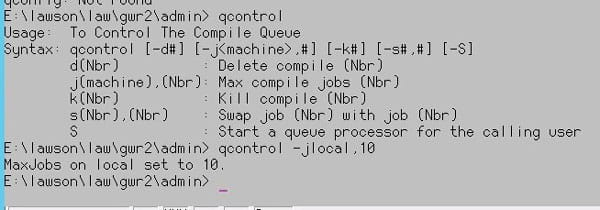
When doing a patch compile or a product line compile, it is best to increase the number of jobs that can be added to the queue so they will compile faster. The default is two jobs. To increase the number of jobs, use the command “qcontrol -j<machine name>,#”
For example:

Many ERP systems allow for a much longer location ID than Lawson does.
Many Punch Out vendors have limitations on the size of the location ID. Make sure to validate with any Punch Out vendors you may have before you come up with a new location naming convention. Otherwise you may have to revisit this item later.

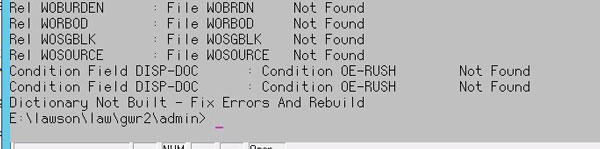
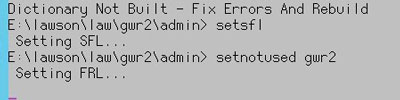
If you are performing a blddbdict as part of database changes, or as part of a product line copy, and you receive the errors “Dictionary Not Built – Fix Errors And Rebuild”, perform the following commands in LID:
setsfl
setnotused <productline>
After that, your blddbdict command should be successful.
blddbdict <productline>

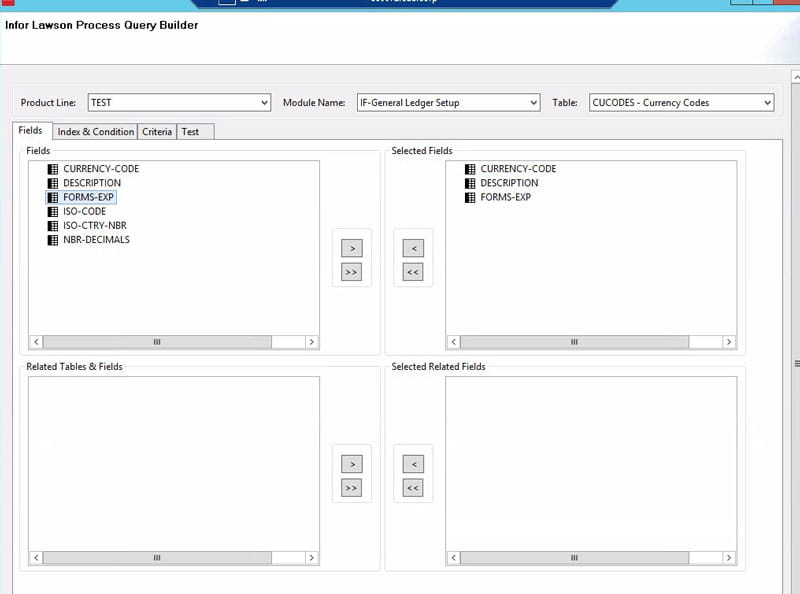
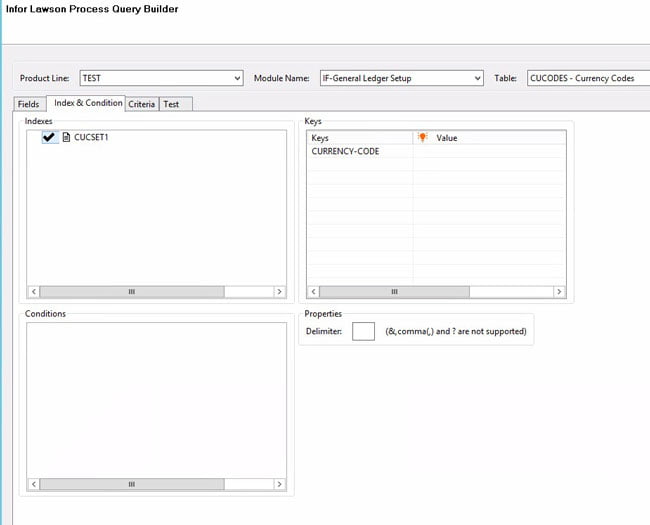
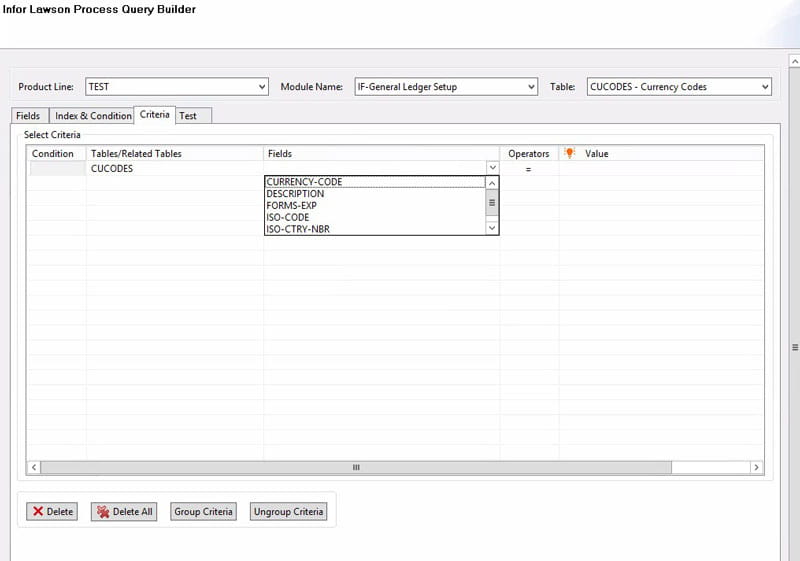
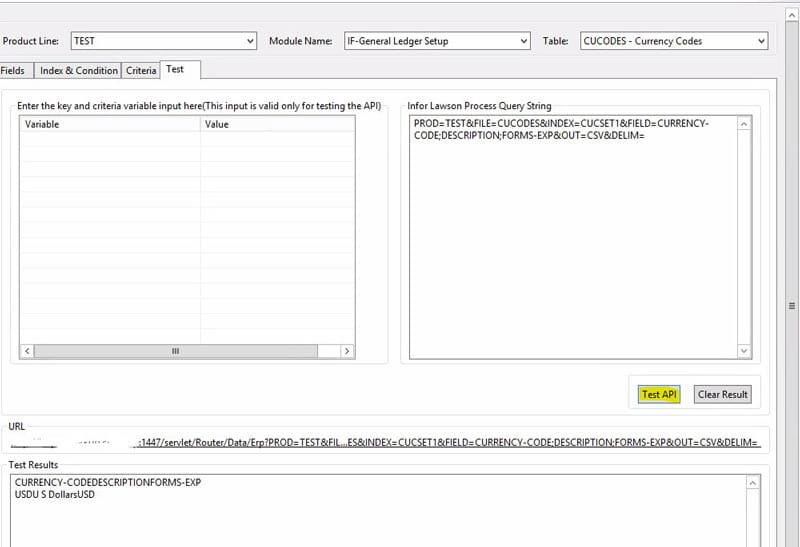
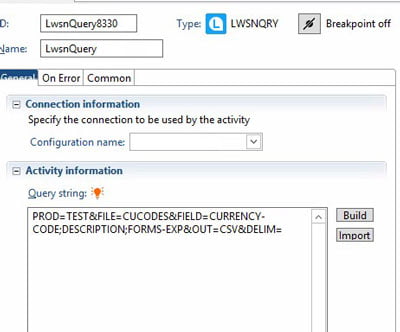
The Lawson query node can be used to query Lawson data using the DME format. In the properties of the node, click “Build” to build your query. Select the product line from which you are trying to get the data. Select the module and the table name where the data resides. Choose the fields that you want to see. You will also have an opportunity to choose related fields from other tables (i.e. a description from a parent table). You can also use an index and provide keys for your query, using either hard-coded values or an IPA variable. On the Criteria tab, you can select other fields besides key index fields to narrow your results. You can use the Test tab if you don’t have any variables in your query.
Use the Landmark Transaction node to query or update Landmark data. In the properties window, select “Build” and you will be presented with a wizard to help you build your Landmark query.
![]()
Select the data area that you are querying/updating. Select the Module and Object Name. (HINT: these values can be found by using Ctrl+Shift+Click on the form in Rich Client or the Landmark Web UI).
Choose your action. There are basic CRUD (create, read, update, delete) actions for each object, and there will be more actions specific to the object you selected. Action Operator will likely be “NONE”. Select your action type (SingleRecordQuery, MultipleRecordQuery, etc.), and finally select the criteria. Click OK.
![]()
Decide whether to use the hardcoded values for your transaction field values. You can supply variables here to make your flow more portable.
![]()
![]()

Security on activity groups is handled outside of LSA. If users are getting a “security violation for activity group” when they try to add a batch job in the activities module, you will need to do a little extra security maintenance.
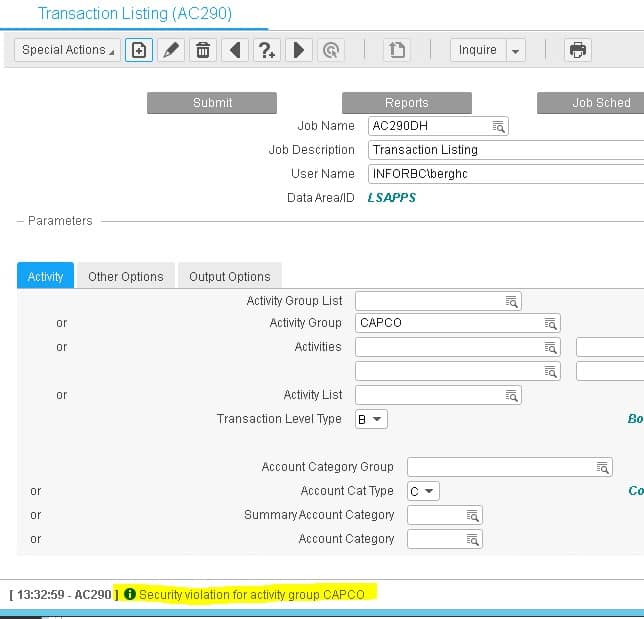
First, go to AC00 and make note of the value in the “Security” field.
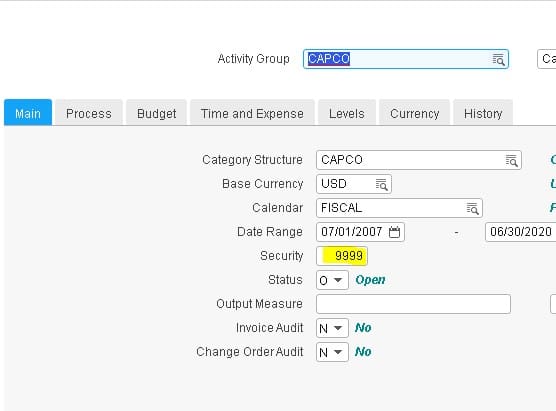
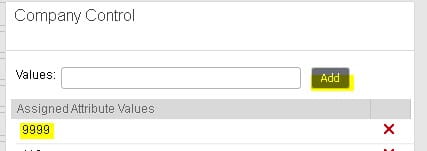
Next, open the user’s security record in ISS or LSA and navigate to the “Company Control” field. Click on the search and make sure that “Security” value is in the user’s company list. If not, add it. Then clear out the security cach and perform an IOSCacheRefresh.


AP Invoices only flow to Asset Management when there is an Asset Template associated with the AP invoice distribution line.
The invoices appear on AM15 and can be then added to AM or not depending on the actual need.
AP invoices do not automatically create assets, they need to be reviewed on AM15 and all aspects of the information that appears there is able to be adjusted before the invoice becomes an Asset.

Recently we ran into the dreaded “Unable to load” error message in Portal, and could not find any indication of why Portal couldn’t load. The most we could see through a Fiddler trace is that the sso.js file was getting a 500 error. There was nothing logged anywhere. Not on the WebSphere node, application server, nothing in ios, security, event viewer. Nothing! We figured WebSphere had to be the culprit, because sso.js is wrapped up in an ear file in WAS_HOME, and everything on the Portal side was working until it tried to hit that script. So, we started digging into WebSphere and figured out that one of the certs was expired on the Node. For some reason, a custom wildcard cert had been used for the WebSphere install on the node only. We opted to switch it to use the default self-signed cert, which was not expired, and was the solution that worked best for us. Another option would, of course, be to upload a new wildcard cert and switch the old one to the new one.
To switch a cert in WebSphere, go to Security > SSL certificate and key management > Key stores and certificates. Select the NodeDefaultKeyStore of the node you want to change, and under additional properties on the right, select “Personal certificates”. Click your “old” cert and select “Replace”. Select the “new” certificate that is replacing the old one. Check the “Delete old Certificate after replacement” box.
Bounce WebSphere services, or better yet, reboot. And you should be good to go!