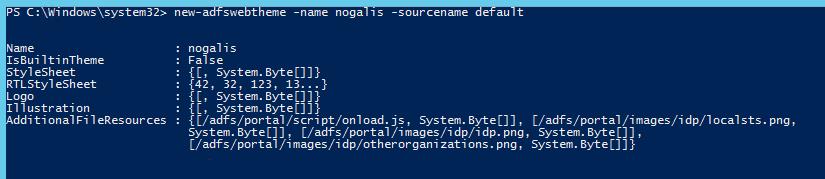
The theme name that is delivered with the AD FS configuration is “default”, but you have the option of creating and customizing your own themes. To create a custom theme, open PowerShell as administrator on the AD FS server, and type the command:
new-adfswebtheme -name <your theme name> -sourcename <the theme to copy>
For your first theme, you will probably want to use “default” as the source.
To activate your theme, type command:
set-adfswebconfig -activatethemename <your theme name>