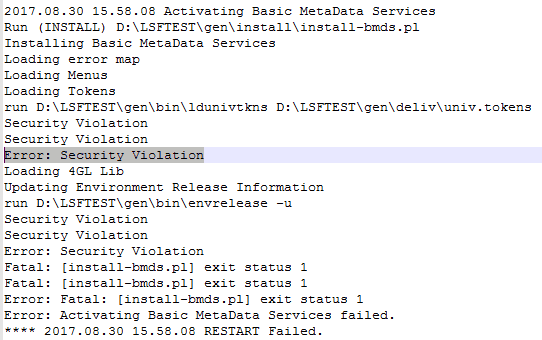
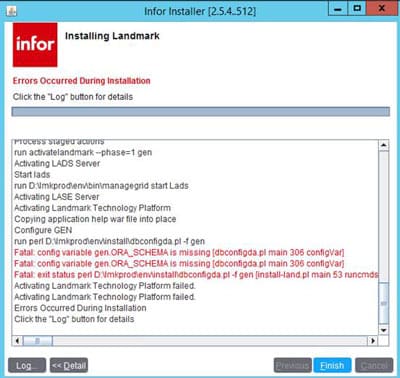
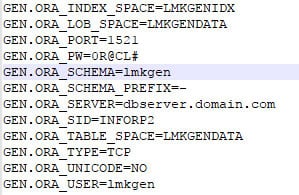
After completing federation and restarting LSF and Landmark, landmark authentication fails. The security authen log returns the following error: sun.security.validator.ValidatorException: PKIX path building failed.
This can happen if secured ldap bind is being used. With the secured ldap bind (using ldaps protocol and port 636), the certificates from the AD server are missing from the java keystore on the landmark server. This can happen even if you are using SSOP on LSF for authentication. To resolve the issue, export the certificates from the AD server and import them into the java keystore. If LSF was bound to AD, the certificates should already be on the LSF box. They can be copied over from LSF and imported to the keystore on the landmark server using the following example.
D:\JDK\bin\keytool.exe -keystore D:\JDK\jre\lib\security\cacerts -importcert -alias ADca –file D:\cacert.cer
D:\JDK\bin\keytool.exe -keystore D:\JDK\jre\lib\security\cacerts -importcert -alias ADroot –file D:\root.cer
Error:
Wed May 31 09:49:13.112 MDT 2017 – default-724934462: Error encountered while getting users DN. Please see logs for details[egn1ldmam2ike26udaqvs9rs2g]Could Not Bind With privileged identity. User [lawson]simple bind failed:ldap.domain.com:636
Stack Trace :
javax.naming.CommunicationException: simple bind failed: ldap.domain.com:636 [Root exception is javax.net.ssl.SSLHandshakeException: sun.security.validator.ValidatorException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target]
at com.sun.jndi.ldap.LdapClient.authenticate(LdapClient.java:219)
at com.sun.jndi.ldap.LdapCtx.connect(LdapCtx.java:2788)
at com.sun.jndi.ldap.LdapCtx.<init>(LdapCtx.java:319)
at com.sun.jndi.ldap.LdapCtxFactory.getUsingURL(LdapCtxFactory.java:192)
at com.sun.jndi.ldap.LdapCtxFactory.getUsingURLs(LdapCtxFactory.java:210)
at com.sun.jndi.ldap.LdapCtxFactory.getLdapCtxInstance(LdapCtxFactory.java:153)
at com.sun.jndi.ldap.LdapCtxFactory.getInitialContext(LdapCtxFactory.java:83)
at javax.naming.spi.NamingManager.getInitialContext(NamingManager.java:684)
at javax.naming.InitialContext.getDefaultInitCtx(InitialContext.java:313)
at javax.naming.InitialContext.init(InitialContext.java:244)
at javax.naming.InitialContext.<init>(InitialContext.java:216)
at javax.naming.directory.InitialDirContext.<init>(InitialDirContext.java:101)
at com.lawson.security.authen.LawsonLDAPBindLoginProcedure.getDNForUser(LawsonLDAPBindLoginProcedure.java:446)
at com.lawson.security.authen.LawsonLDAPBindLoginProcedure._authenticate(LawsonLDAPBindLoginProcedure.java:233)
at com.lawson.security.authen.LawsonLDAPBindLoginProcedure.authenticate(LawsonLDAPBindLoginProcedure.java:681)
at com.lawson.security.authen.LawsonLoginSchemeImpl.authenticate(LawsonLoginSchemeImpl.java:1701)
at com.lawson.security.authen.LawsonProgrammaticAuthenticatorImpl.authenticate(LawsonProgrammaticAuthenticatorImpl.java:198)
at com.lawson.security.authen.LawsonProgrammaticAuthenticatorImpl.authenticate(LawsonProgrammaticAuthenticatorImpl.java:100)
at com.lawson.rdtech.gridadapter.provider.LmrkSessionProvider.createGridPrincipal(LmrkSessionProvider.java:287)
at com.lawson.rdtech.gridadapter.provider.LmrkSessionProvider.validatePassword(LmrkSessionProvider.java:254)
at com.lawson.rdtech.gridadapter.provider.AbstractSessionProviderBase.logon(AbstractSessionProviderBase.java:134)
at com.lawson.rdtech.gridadapter.provider.LmrkSessionProvider.logon(LmrkSessionProvider.java:159)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at com.lawson.grid.proxy.ProxyServerImpl$ProxyRequestThread.invoke(ProxyServerImpl.java:2715)
at com.lawson.grid.proxy.ProxyServerImpl$ProxyRequestThread.processRequest(ProxyServerImpl.java:2502)
at com.lawson.grid.proxy.ProxyServerImpl$ProxyRequestThread.runThread(ProxyServerImpl.java:2425)
at com.lawson.grid.util.thread.PooledThread.run(PooledThread.java:137)
at java.lang.Thread.run(Thread.java:745)
Caused by: javax.net.ssl.SSLHandshakeException: sun.security.validator.ValidatorException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
at sun.security.ssl.Alerts.getSSLException(Alerts.java:192)
at sun.security.ssl.SSLSocketImpl.fatal(SSLSocketImpl.java:1949)
at sun.security.ssl.Handshaker.fatalSE(Handshaker.java:302)
at sun.security.ssl.Handshaker.fatalSE(Handshaker.java:296)
at sun.security.ssl.ClientHandshaker.serverCertificate(ClientHandshaker.java:1514)
at sun.security.ssl.ClientHandshaker.processMessage(ClientHandshaker.java:216)
at sun.security.ssl.Handshaker.processLoop(Handshaker.java:1026)
at sun.security.ssl.Handshaker.process_record(Handshaker.java:961)
at sun.security.ssl.SSLSocketImpl.readRecord(SSLSocketImpl.java:1062)
at sun.security.ssl.SSLSocketImpl.performInitialHandshake(SSLSocketImpl.java:1375)
at sun.security.ssl.SSLSocketImpl.writeRecord(SSLSocketImpl.java:747)
at sun.security.ssl.AppOutputStream.write(AppOutputStream.java:123)
at java.io.BufferedOutputStream.flushBuffer(BufferedOutputStream.java:82)
at java.io.BufferedOutputStream.flush(BufferedOutputStream.java:140)
at com.sun.jndi.ldap.Connection.writeRequest(Connection.java:426)
at com.sun.jndi.ldap.Connection.writeRequest(Connection.java:399)
at com.sun.jndi.ldap.LdapClient.ldapBind(LdapClient.java:359)
at com.sun.jndi.ldap.LdapClient.authenticate(LdapClient.java:214)
… 30 more
Caused by: sun.security.validator.ValidatorException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
at sun.security.validator.PKIXValidator.doBuild(PKIXValidator.java:387)
at sun.security.validator.PKIXValidator.engineValidate(PKIXValidator.java:292)
at sun.security.validator.Validator.validate(Validator.java:260)
at sun.security.ssl.X509TrustManagerImpl.validate(X509TrustManagerImpl.java:324)
at sun.security.ssl.X509TrustManagerImpl.checkTrusted(X509TrustManagerImpl.java:229)
at sun.security.ssl.X509TrustManagerImpl.checkServerTrusted(X509TrustManagerImpl.java:124)
at sun.security.ssl.ClientHandshaker.serverCertificate(ClientHandshaker.java:1496)
… 43 more
Caused by: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target
at sun.security.provider.certpath.SunCertPathBuilder.build(SunCertPathBuilder.java:141)
at sun.security.provider.certpath.SunCertPathBuilder.engineBuild(SunCertPathBuilder.java:126)
at java.security.cert.CertPathBuilder.build(CertPathBuilder.java:280)
at sun.security.validator.PKIXValidator.doBuild(PKIXValidator.java:382)
… 49 more
Wed May 31 09:49:13.113 MDT 2017 – default-724934462: Error encountered while getting users DN. Please see logs for details[egn1ldmam2ike26udaqvs9rs2g]Could Not Bind With privileged identity.
Wed May 31 09:49:13.113 MDT 2017 – default-724934462: Failed to get DN for user: lawson