
Using Bulk Insert for interfaces
Bulk Insert (delivered with SQL Server) is a great way to quickly import data into SQL Server tables. The input file format does not need to match the column definition on the table. You can use import file definitions for that.
To create an import file definition, first go to the SQL server where the database table resides. Run the command bcp <database>.<owner>.<tablename> format nul -c -f <local path>\<filename>.fmt -t, -T
(For clarity, best practice is to name the file the same as the table name).
Edit the format file (if needed) in a text editor to accommodate for any differences between the input file and the database table. The first column is the order of fields in the input file. The 5th column provides the delimiter between fields. The 6th column maps to the appropriate field in the database table. The number at the top (below the version “10.0”) describes how many fields are in the input file. If you are not using all the fields from the input file, you must adjust this number accordingly. If you say it is looking for 20 fields, it will be looking for 20 fields and will error if 20 fields aren’t found.
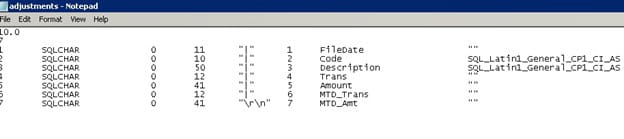
CSV files are a little tricky, as you need to accommodate for double quotes.
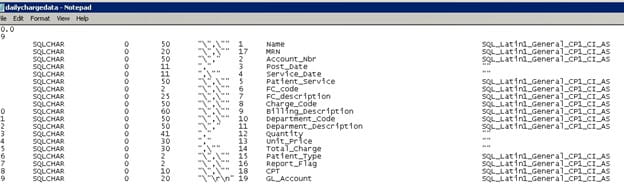
Note that the files must be accessible by a local path on the SQL Server machine.
The Bulk Insert command is:
BULK INSERT <table name>
FROM ‘<full path to import file>
WITH (FORMATFILE = ‘<full path to format file>’, FIRSTROW = <first row of data in the import file>)
