
Top Takeaways from “Process Automation – Performance Considerations and Best Practices” Infor Webinar
This 1 hour, interactive briefing from Infor provides an overview of the best practices for performance tuning your IPA process flows, grid tuning considerations, and tips to leverage the most from your system.
The full webinar can be accessed through a link on this page: (https://technology-blog.infor.com/2015/12/13/recording-now-available-for-ipa-performance-considerations-and-best-practices-webinar/)
Here are some notable takeaways from the video:
- IPA Settings Tuning
Basic tips for improving performance:- Ensure you are on the latest release of Landmark Environment.
- Upgrading your system to a newer release of Java will often result in performance improvements.
- Core Pool Size: pfi.dispatcher.CorePoolSize setting within Grid determines how many simultaneous workunits can process at a time. Rule of thumb is to start by setting this value to the number of CPU Cores in your Landmark Server. (8 core CPU = 8 max workunits) In order to fully optimize, you can start simultaneous flows equal to your server’s cores and check Task Manager’s Performance tab. For example, if only 50% of your CPU is being used with 8 simultaneous flows in progress, you can probably safetly increase the maximum workunits to 12 or even 16 for improved performance.
- Max Heap: grid.jvm.maxHeapMB setting within Grid sets the max amount of server RAM a particular Grid Node can use for processing. When setting this value, be aware of how much total RAM is available to use on the server. All the Max Heap sizes for all Grid Nodes, Operating System Memory, and Memory Footprint of other programs needs to be less than the total RAM of the server. The Max Heap should be set as high as possible with these considerations in mind.
- LmrkDeferred Node: When installing Landmark, some grid deployments create this LmrkDeferred grid gode which combines the functionality of Async and IPA into one node. You should not be running Process Automation with this grid node. Infor recommends that the Async node and IPA node be broken out into their own grid nodes.
- Configure the system so that there is only one IPA Grid node per Data Area that processes workunits.
- Process Tuning
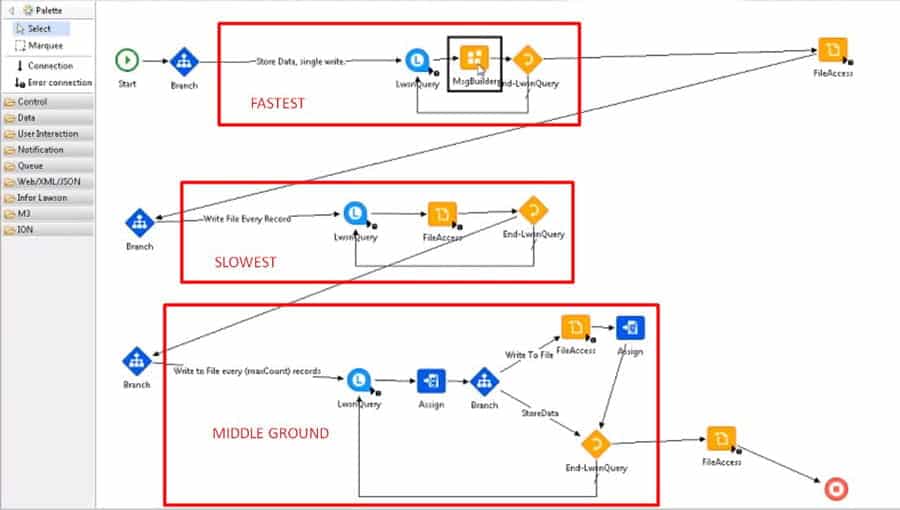
Basic tips for improving processes/flows:- Most important factor is the number of nodes. Try to minimize the number of nodes in your flow as flows take approximately 5-20ms time between nodes and 2-5ms time per variable assignment. An important tip when trying to reduce nodes is to remember that values returned from a query or processing node will automatically be assigned an internal variable name that we can refer to. There is no need for an additional assignment.
- When using a query to cycle through records and write to a file, using a MsgBuilder versus a FileAccess or Assign node is more efficient as it is keeping the records in memory to write all at once at a later time. FileAccess in between a query is the most inefficient as it requires opening and appending onto a file once for every record encountered.

- Turning on logging will decrease flow performance so it should only be turned on when troubleshooting flow failure or performance issues. When a flow is failing, turn on Workunit and Activity Logging and turn this off when done troubleshooting. For performance issues, run the flow with Workunit only logging turned on.
- When creating a large csv file, consider using SysCommand node instead of writing to a file by looping through records.
For more details and the most recently updated KB articles, refer/subscribe to:
KB 1671693 – IPA Support Best Practices
